Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- PREPRINT
 Believing without Seeing: Quality Scores for Contextualizing Vision-Language Model ExplanationsKeyu He, Tejas Srinivasan, Brihi Joshi, and 3 more authorsUnder Review, 2025
Believing without Seeing: Quality Scores for Contextualizing Vision-Language Model ExplanationsKeyu He, Tejas Srinivasan, Brihi Joshi, and 3 more authorsUnder Review, 2025When people query Vision-Language Models (VLMs) but cannot see the accompanying visual context (e.g. for blind and low-vision users), augmenting VLM predictions with natural language explanations can signal which model predictions are reliable. However, prior work has found that explanations can easily convince users that inaccurate VLM predictions are correct. To remedy undesirable overreliance on VLM predictions, we propose evaluating two complementary qualities of VLM-generated explanations via two quality scoring functions. We propose Visual Fidelity, which captures how faithful an explanation is to the visual context, and Contrastiveness, which captures how well the explanation identifies visual details that distinguish the model’s prediction from plausible alternatives. On the A-OKVQA and VizWiz tasks, these quality scoring functions are better calibrated with model correctness than existing explanation qualities. We conduct a user study in which participants have to decide whether a VLM prediction is accurate without viewing its visual context. We observe that showing our quality scores alongside VLM explanations improves participants’ accuracy at predicting VLM correctness by 11.1%, including a 15.4% reduction in the rate of falsely believing incorrect predictions. These findings highlight the utility of explanation quality scores in fostering appropriate reliance on VLM predictions.
- ACL Findings 2025
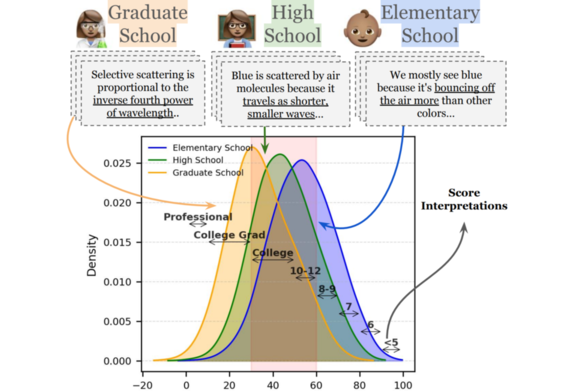 ELI-Why: Evaluating the Pedagogical Utility of LLM ExplanationsBrihi Joshi*, Keyu He*, Sahana Ramnath, and 5 more authorsACL Findings, 2025
ELI-Why: Evaluating the Pedagogical Utility of LLM ExplanationsBrihi Joshi*, Keyu He*, Sahana Ramnath, and 5 more authorsACL Findings, 2025Language models today are widely used in education, yet their ability to tailor responses for learners with varied informational needs and knowledge backgrounds remains under-explored. To this end, we introduce ELI-WHY, a benchmark of 13.4K "Why" questions to assess the pedagogical capabilities of LLMs. We then conduct two extensive human studies to assess the utility of LLM-generated explanatory answers (explanations) on our benchmark, tailored to three distinct educational grades: elementary, high-school, and graduate school. In our first study, human raters assume the role of an "educator" to assess model explanations’ fit to different educational grades. We find that GPT-4-generated explanations match their intended educational background only 50% of the time, compared to 79% for human-curated explanations. In our second study, human raters assume the role of a learner to assess if an explanation fits their own informational needs. Results show that users deemed GPT-4-generated explanations relatively 20% less suited to their informational needs, particularly for advanced learners. Additionally, automated evaluation metrics reveal that GPT-4 explanations for different informational needs remain indistinguishable in their grade-level, limiting their pedagogical effectiveness. These findings suggest that LLMs’ ability to follow inference-time instructions alone is insufficient for producing high-utility explanations tailored to users’ informational needs.
- ICLR 2025
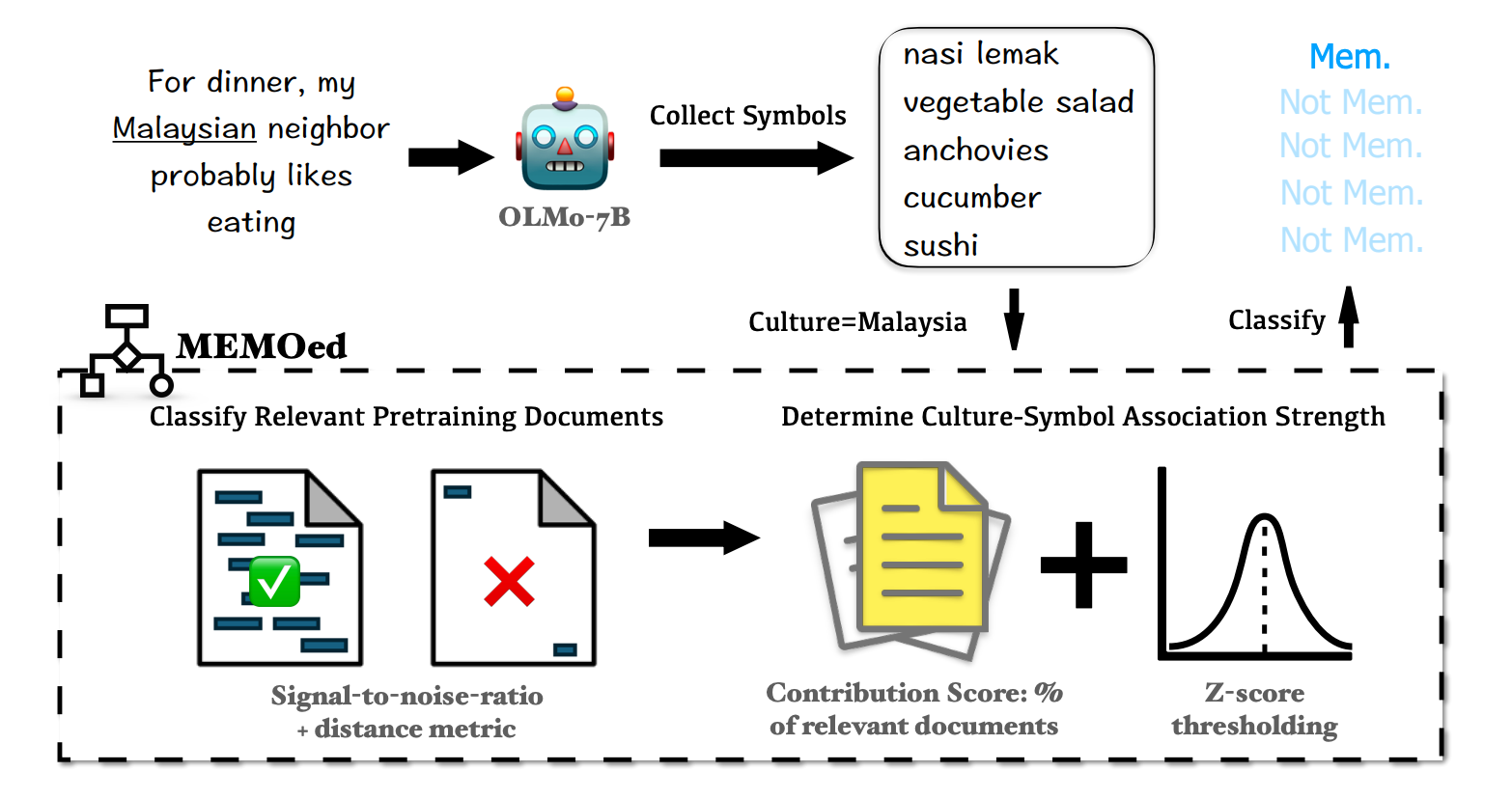 Attributing Culture-Conditioned Generations to Pretraining CorporaHuihan Li*, Arnav Goel*, Keyu He, and 1 more authorICLR, 2025
Attributing Culture-Conditioned Generations to Pretraining CorporaHuihan Li*, Arnav Goel*, Keyu He, and 1 more authorICLR, 2025In open-ended generative tasks like narrative writing or dialogue, large language models often exhibit cultural biases, showing limited knowledge and generating templated outputs for less prevalent cultures. Recent works show that these biases may stem from uneven cultural representation in pretraining corpora. This work investigates how pretraining leads to biased culture-conditioned generations by analyzing how models associate entities with cultures based on pretraining data patterns. We propose the MEMOed framework (MEMOrization from pretraining document) to determine whether a generation for a culture arises from memorization. Using MEMOed on culture-conditioned generations about food and clothing for 110 cultures, we find that high-frequency cultures in pretraining data yield more generations with memorized symbols, while some low-frequency cultures produce none. Additionally, the model favors generating entities with extraordinarily high frequency regardless of the conditioned culture, reflecting biases toward frequent pretraining terms irrespective of relevance. We hope that the MEMOed framework and our insights will inspire more works on attributing model performance on pretraining data.



2023
- Tech Report
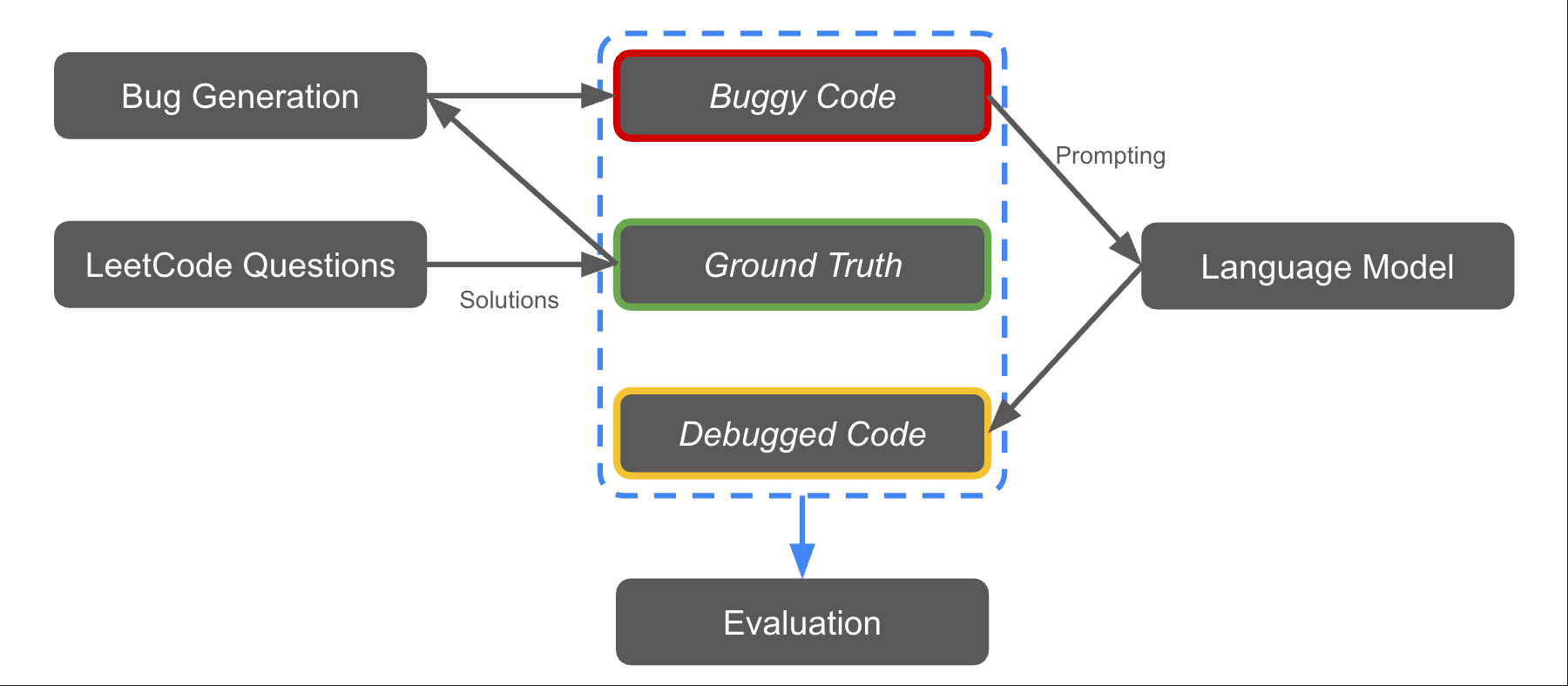 Enhancing Debugging Skills of LLMs with Prompt EngineeringKeyu He*, Max Li*, and Joseph Liu*Tech Report, Dec 2023
Enhancing Debugging Skills of LLMs with Prompt EngineeringKeyu He*, Max Li*, and Joseph Liu*Tech Report, Dec 2023This paper presents a comprehensive study on improving the debugging capabilities of Large Language Models (LLMs) like GPT-3.5, focusing on the application of prompt engineering techniques. We explore the efficacy of few-shot learning, chain-of-thought prompting, and a baseline zero-shot model in enhancing LLMs’ ability to debug code. Utilizing static and dynamic evaluation metrics, the study rigorously assesses the debugging proficiency of these models. By introducing different types of bugs, including procedural and language model-generated errors, and applying varied prompting strategies, we provide a deeper understanding of LLMs’ debugging capabilities. The results provide insights into the limitation of debugging capabilities of GPT-3.5 Turbo, even with the assistance of various prompting techniques. Source code of our evaluation method and bug generation techniques are in GitHub repository: https://github.com/FrankHe2002/CSCI499FinalProject.
